AI as infrastructure, not magic.
Every AI feature I have built starts with the same question: what is the human doing today that AI can do better, faster, or at a scale that would otherwise be impossible? Not: "what LLM capability can we wrap in a product?"
The second question is always: how will we know if it worked? AI features that ship without a measurement plan are experiments, not products. Every feature in this case study has a success metric that was defined before the first line of prompt engineering.
"An AI feature without an evaluation strategy is a liability. You can't improve what you can't measure — and in AI, what you can't measure will eventually fail you at the worst possible time."
AI features shipped
- AI copilot with RAG-grounded response generation (Thena)
- L1 deflection agent with per-channel knowledge scoping (Thena)
- Sentiment scoring and priority surfacing (Thena)
- AI evaluation framework: offline + in-product telemetry (Thena)
- AI ticket automation suite (Zapier)
- AI-driven upsell recommendation engine (Zapier)
AI copilot — from 0→1.
The problem
Support agents at Thena's customers were manually drafting every response from scratch. Even for questions that had been answered dozens of times before. The knowledge existed — in docs, in previous tickets, in internal wikis — but agents had to find it themselves on every interaction.
The hypothesis
If we could surface an AI-generated draft response grounded in the customer's own knowledge base, agents would accept and edit it rather than starting from blank. We'd reduce handle time and improve response consistency without removing human judgement from the loop.
Knowledge architecture
Multi-source RAG pipeline ingesting URLs, PDFs, internal docs, and historical resolved tickets. Configurable chunking and retrieval tuned per customer's content type and query distribution.
Response generation
Grounded generation with configurable answer length and tone. System prompts scoped per workspace. Fallback behaviour when knowledge base coverage is insufficient — never hallucinate, always acknowledge gaps.
Human-in-the-loop
Every AI response is presented as a draft — agents can edit, regenerate, or discard. No AI response auto-sends without agent review. The product is an accelerator, not an autonomous responder.
L1 queries deflected before reaching a human agent via the AI copilot and web chat combo. Measured against pre-launch baseline across the same accounts.
Agents using the copilot resolved tickets significantly faster than without it. Draft acceptance rate was high enough that the net AHT impact was material, not marginal.
L1 deflection — autonomous front-line response.
Where the copilot assists human agents, L1 Deflection operates autonomously — responding to inbound customer requests in Slack channels before a human agent ever sees them. It is configurable per-channel, with independent knowledge sources and answer configurations per assistant.
The hardest product decision here was defining failure gracefully. An autonomous AI that gives wrong answers is worse than no AI. We built explicit fallback rules: if confidence below threshold, escalate to human immediately and flag for review. Every escalation is a training signal.
Configuration surface
- Per-channel agent configuration with independent knowledge scoping
- Source sync status monitoring: processing / synced / failed states
- Configurable answer length, confidence thresholds, and escalation rules
- Duplicate sources across assistants without redundant setup
- Enable/disable per workspace with permission-gated access control
- Live source sync with on-demand re-sync capability
"Deflection is only valuable if the deflected answer is correct. The first KPI we tracked was not deflection rate — it was deflection accuracy. Getting that right first is what made deflection rate a meaningful number."
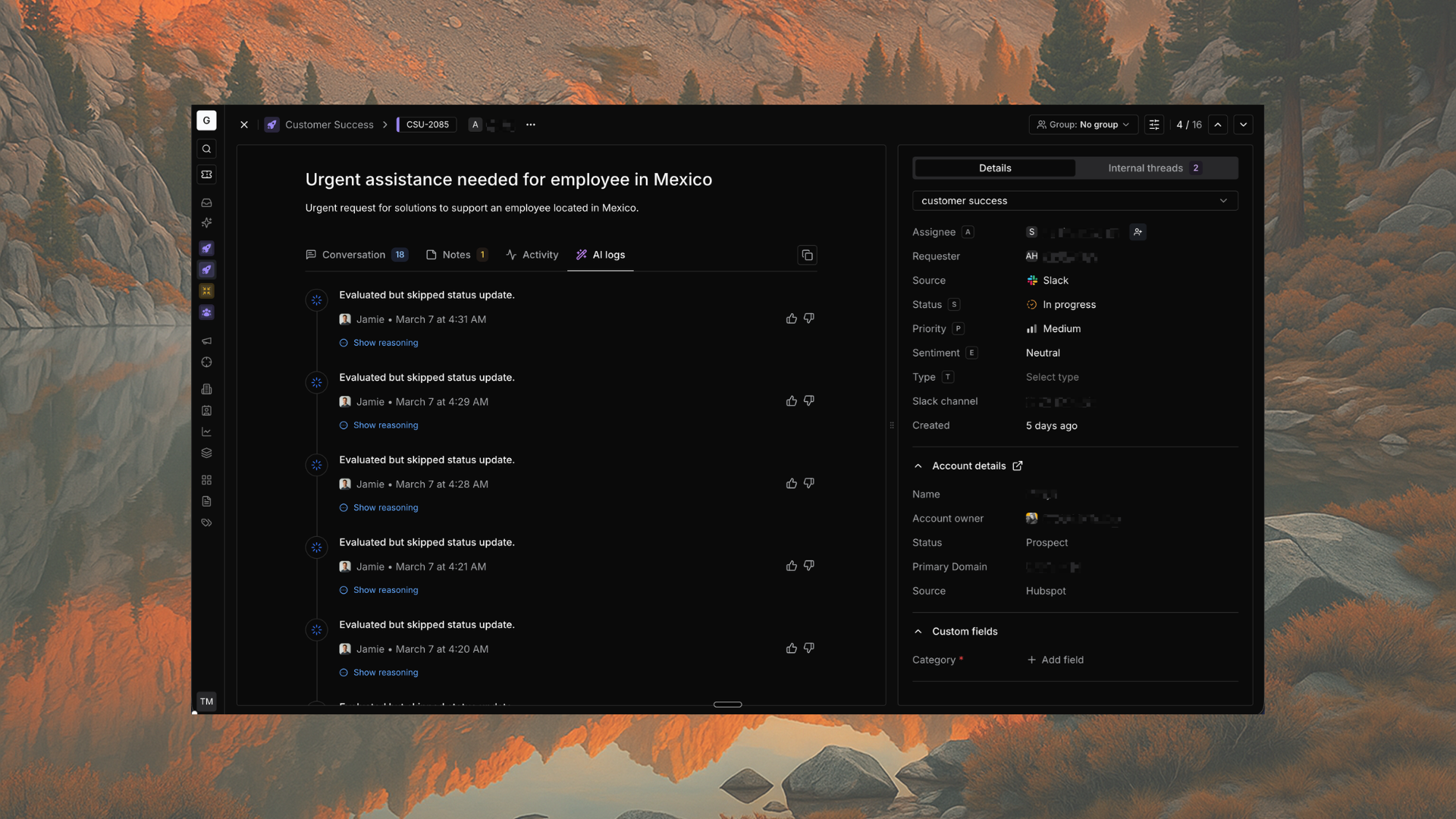
The AI evaluation framework — how we knew it was working.
Every AI feature Thena shipped was backed by an evaluation strategy before it went to production. This is not the glamorous part of AI product development — but it is the part that determines whether the glamorous features actually hold up.
The framework had two layers: offline testing against a curated evaluation set, and in-product telemetry tracking grounding quality, acceptance rates, and failure modes in real usage.
What we measured
- Grounding coverage: % of responses with verifiable source citations
- Accuracy rate: human review of sampled outputs against ground truth
- Hallucination rate: responses containing claims not present in knowledge sources
- Draft acceptance rate: % of AI drafts agents accepted with minimal edits
- Deflection accuracy: % of L1 deflections rated correct by customers (CSAT proxy)
- Failure mode taxonomy: categorised log of every AI error type
92% of all AI responses had verifiable source citations — up from ~65% at initial launch. Improvement driven by iterative RAG tuning guided by the evaluation framework.
Systematic identification and categorisation of failure modes allowed targeted fixes. Each sprint included evaluation findings as a first-class input to the prioritisation process.
Building AI from the support side.
Before owning AI product at Thena, I was the support engineer at Zapier who helped build AI tooling from the other side of the product boundary — as a power user and partner to the product team.
AI ticket automation suite
Partnered with product and engineering to deliver AI-powered ticket summarisation, draft reply generation, and troubleshooting suggestion features across Zapier's 50+ agent support team. Reduced email handle time by 13%, saving 400+ hours per month. I was the primary product partner defining requirements from the support workflow perspective.
AI upsell recommendation engine
Designed an AI-driven recommendation engine that analysed customer usage data and workflow patterns to surface upsell opportunities at the moment of maximum relevance. Increased advanced feature adoption by 15% and generated a $100K+ quarterly pipeline. The insight: support interactions are the highest-signal moment for product-led growth.
How I think about shipping AI that works.
-
01
Start with the human workflow, not the model capability
Map what the human is doing today, step by step. Identify the highest-friction, most repetitive, or most error-prone step. That is where AI should enter — replacing a specific action, not the entire flow. Avoid the trap of "what can the LLM do?" and start with "what is the user trying to accomplish?"
-
02
Define failure modes before defining success
Every AI feature has a failure mode that is worse than not having the feature at all. Define it explicitly before you ship. For a response copilot: hallucination. For deflection: wrong answer that damages customer trust. For sentiment scoring: false positive that misprioritises a critical account. Know your worst case and build guardrails around it.
-
03
Measure the right thing, not the easy thing
Deflection rate is easy to measure but meaningless without deflection accuracy. Draft acceptance rate is easy to measure but meaningless without understanding edit depth. Build measurement that captures quality, not just volume. The signal-to-noise ratio of your evaluation data determines how fast you can improve.
-
04
Keep humans in the loop until trust is earned
AI features should earn autonomy incrementally. Start with AI-assist (human reviews every output), graduate to AI-default (human can override), then to AI-autonomous (human is notified, not required). Move between levels based on measured accuracy, not time elapsed or pressure to ship faster.
-
05
Every AI sprint has an evaluation pass
Evaluation is not a launch gate — it is a continuous practice. Every two weeks, a sample of AI outputs gets reviewed against the ground truth rubric. Every failure mode gets categorised and fed back into prioritisation. The evaluation data is the product roadmap for the AI layer.
The stack behind the product decisions.
I am not an ML engineer, but I am fluent enough in AI infrastructure to have a direct conversation with engineers about implementation tradeoffs — retrieval strategy, chunking logic, context window design, prompt architecture, evaluation rubric design.
That fluency comes from doing, not reading. Every framework and concept below has been used in a shipped product, debugged in production, or stress-tested in an evaluation run.